Leaderboard
Computer-use agents ranked on the 184 MyPCBench tasks — each run under a 100-step budget and graded by the same gemini-3.1-flash-lite-preview rubric judge over the full trajectory. The board is open for submissions: run your model and email us the trajectories and we'll score it and add the row.
Ranking
Sorted by perfect-task rate — the share of tasks for which every rubric item passed. Rubric score is the per-task average with partial credit; trajectory efficiency is rubric score per agent step.
Loading leaderboard…
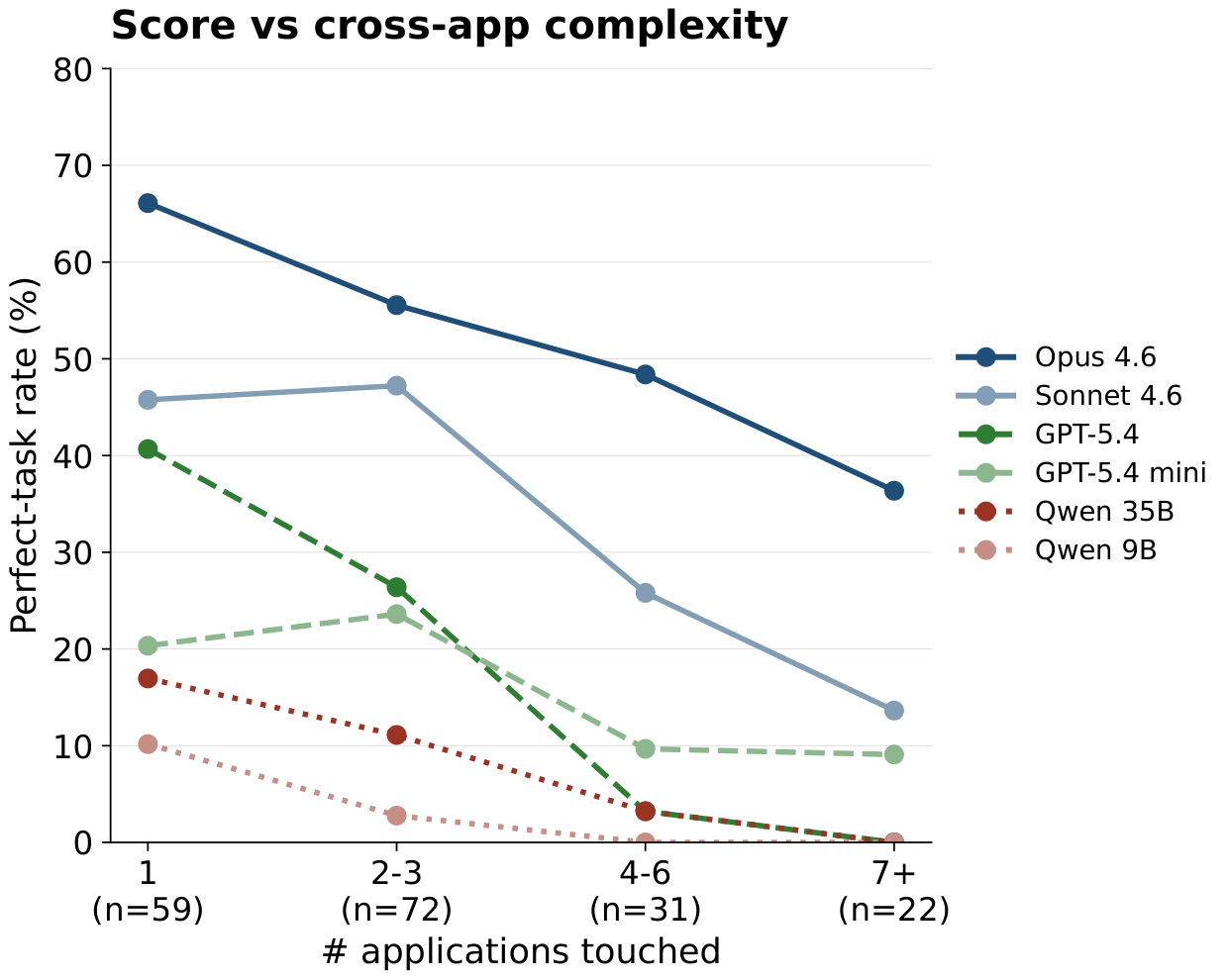
Where the gap opens
The headline gap shows up against task complexity. As soon as a task touches seven or more applications, GPT-5.4 mini, Qwen 35B, and Qwen 9B all drop to 0% perfect, and GPT-5.5 retains just 4.5%. Only the Claude tier and GPT-5.5 perfect any 7+-app task at all, and only Claude Opus 4.6 holds an above-zero rate across every complexity bin.
The per-category heatmap below shows the same pattern by behavioural type: tasks that orchestrate across apps and reconcile across sources collapse first when the agent's context-tracking budget runs out.
Per-category breakdown
Rubric-score percentages, models × six behavioural task categories; green higher, red lower. The decomposition here is the cua-only ablation (computer surface, no bash); the headline aggregates above are the paper's computer+bash run.
Open for submissions
Submit your model
Have a computer-use agent you want on the board? Run it on the public MyPCBench environment and email us the trajectories — we re-grade every submission with the same judge so the numbers stay comparable, then add your row.
- Pull the environment image (
ljang/mypcbench-qemu:latest) and run your agent over all 184 tasks on the unmodified OSWorldpyautoguisurface, 100-step budget. See the harness repo for the runner. - Collect the full trajectories — per-task screenshots and the tool-call/action log — exactly as the harness writes them.
- Email them to us with your model details (below). We re-run the rubric judge over your trajectories and publish the verified row.
- Trajectory filesThe complete per-task trajectories (screenshots + action/tool-call logs) the harness produced. A link to a zip / bucket / HF dataset is fine if they're large.
- Model & contact detailsModel name as it should appear, vendor / lab, whether weights are open or closed, and a contact name + affiliation for the row and any follow-up.
Submissions are re-graded on our side for comparability and reviewed before they appear.